Elasticsearch 기본과 특징
Elasticsearch
목차


Apache Lucene은 Hadoop의 창안자 Doug Cutting에 의해 만들어졌다.
역색인 (Inverted Index) 구조를 가지고 있으며,
Elasticsearch는 Apache Lucene을 기반해 만들어진 오픈소스 검색엔진이다.
Elasticsearch 특징
Index (색인)
Inverted Index (역색인)
| document | keyword |
|---|---|
| 1 | 사람은 다 죽는다. |
| 2 | 소크라테스는 사람이다. |
| 3 | 그러므로 소크라테스는 죽는다. |
| keyword | document |
|---|---|
| 사람 | 1, 2 |
| 소크라테스 | 2, 3 |
| 죽는다 | 1, 3 |
위와 같은 데이터를 가지고 있을 때
색인은 문서를 기준으로 등장하는 키워드를 관리하는데,
역색인은 키워드를 기준으로 키워드가 포함되는 문서를 찾는다.
RDBMS에서 역색인 구조를 사용하려면 LIKE 문법을 사용해야 하는데,
LIKE 문법은 일반적으로 Index를 거치지 않고, Full Table Scan을 하게 된다.
이때 데이터가 많으면 많을수록 속도가 느려진다는 단점이 있다.
Elasticsearch의 경우 데이터를 저장할 때 역색인 구조로 저장하는데,
이것은 책 맨 뒷장의 키워드를 통해 페이지를 찾을 수 있는 찾아보기 페이지와 유사하다.

Text Analysis
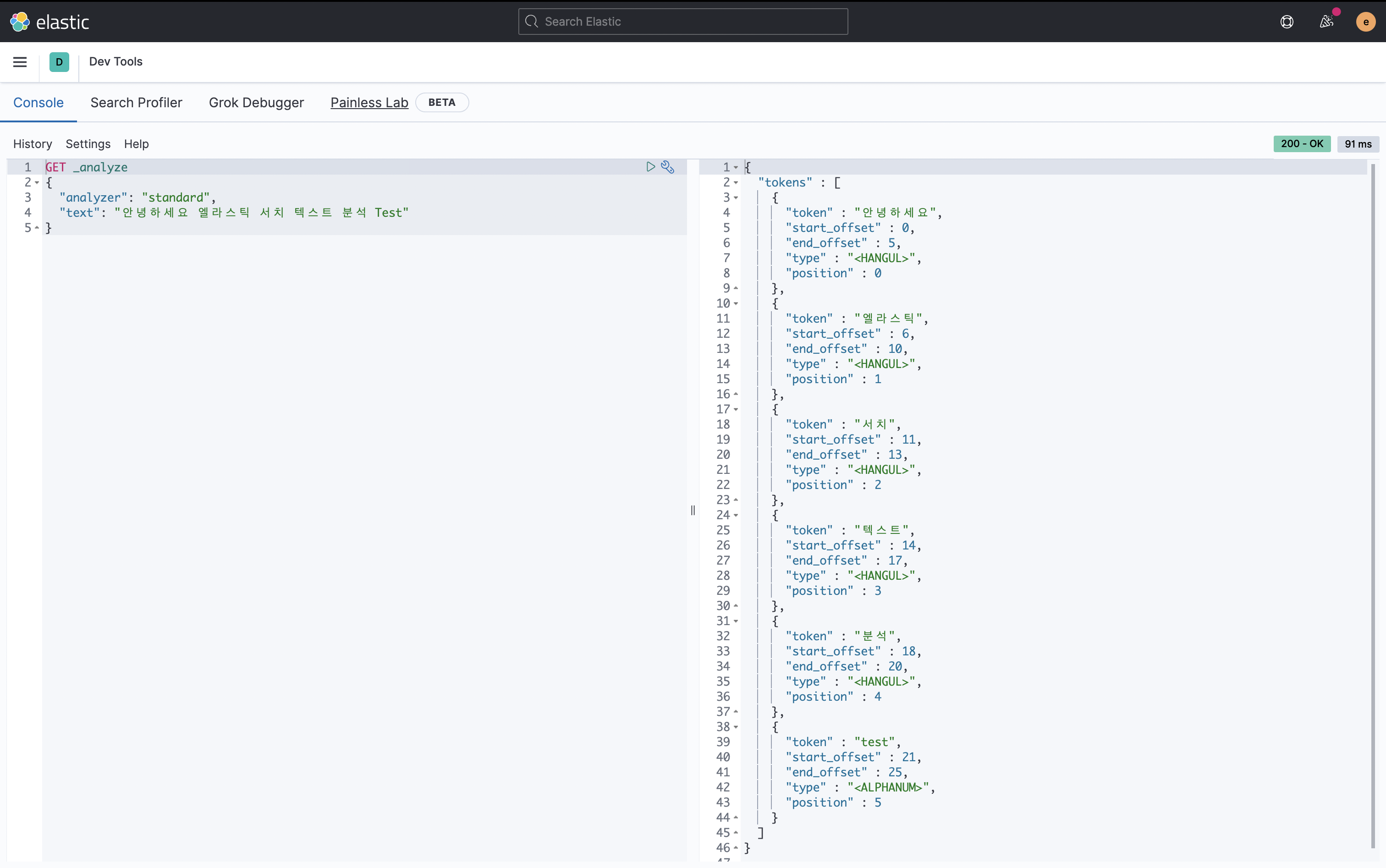
공백을 기준으로 단어가 분리되었고, 이때 분리된 단어를 각각 Term이라고 한다.
영문은 소문자로 변경되며, 문장의 시작과 끝의 offset을 저장한다.
이렇게 단어 단위로 잘라 역색인 구조를 만든다.
이 과정을 Text Analysis라고 하며, 이 과정을 처리하는 기능을 Analyzer 라고 한다.
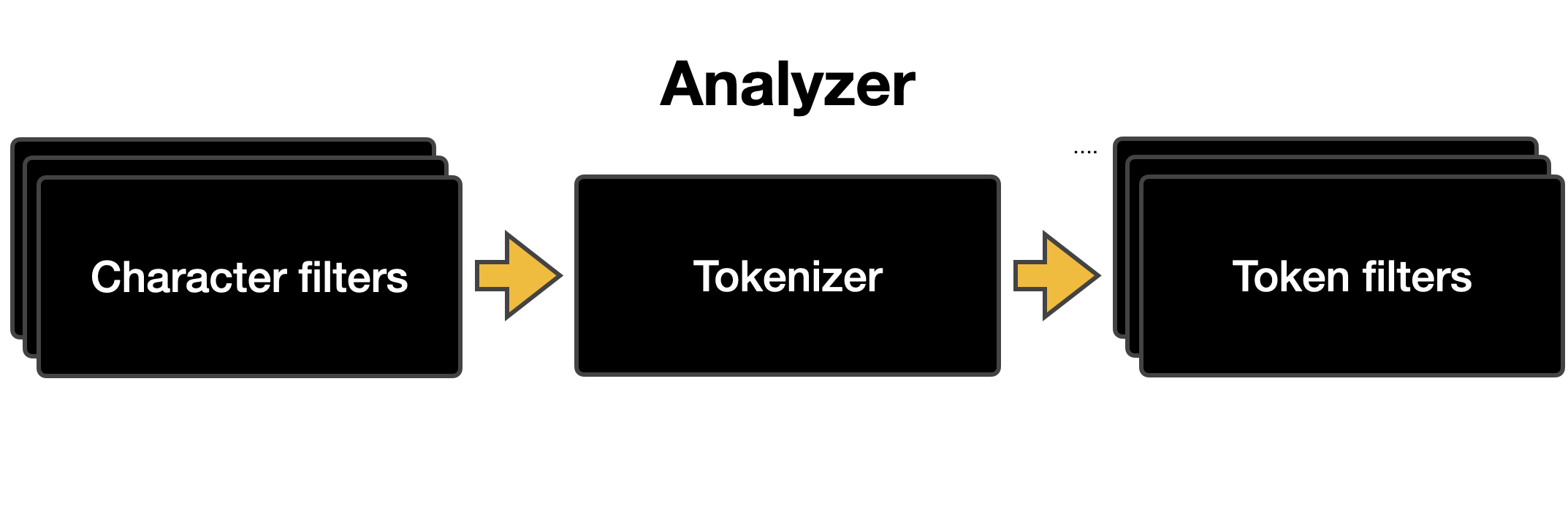
Analyzer는 Character filter 0~3개, Tokenizer 1개, Token filter 0~n개를 가진다.
-
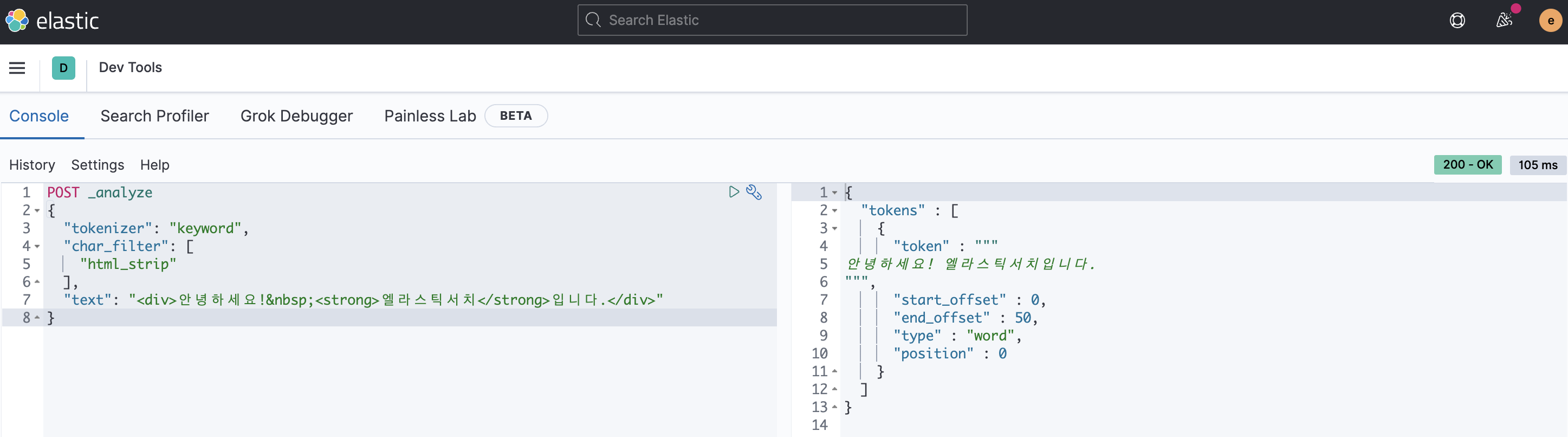
Character filters : Term으로 분리되기 전 수행되는 전 처리 과정
→ HTML 태그 제거, 미리 만들어둔 Mapping Table에서 key 값과 일치하는 value 값으로 치환, 정규식 치환 등 텍스트를 깔끔하게 만들어주는 역할
-
Tokenizer : 정해진 Separator를 기준으로 토큰을 분리한다.
→ Standard : 공백으로 Term을 분리하며, 일부 특수문자 제거한다.
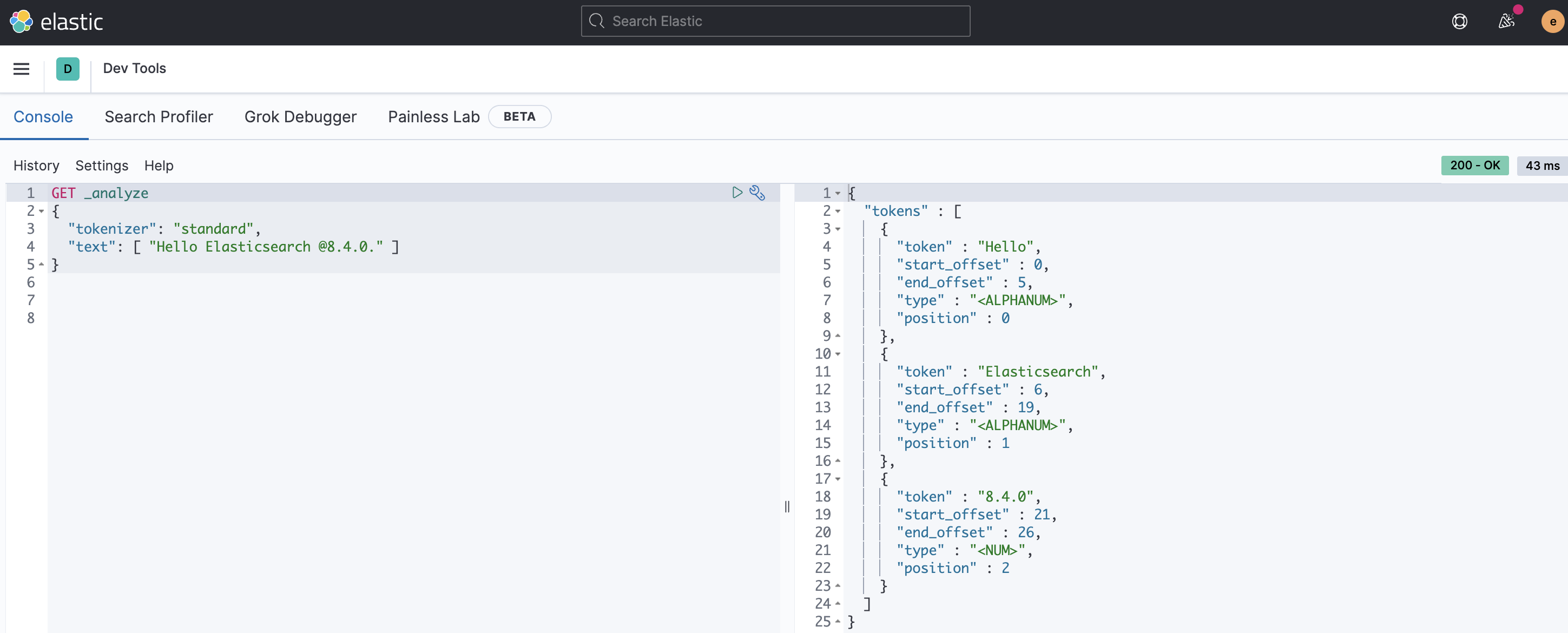
→ Letter : 알파벳 제외한 공백, 숫자, 기호를 기준으로 Term을 분리한다.
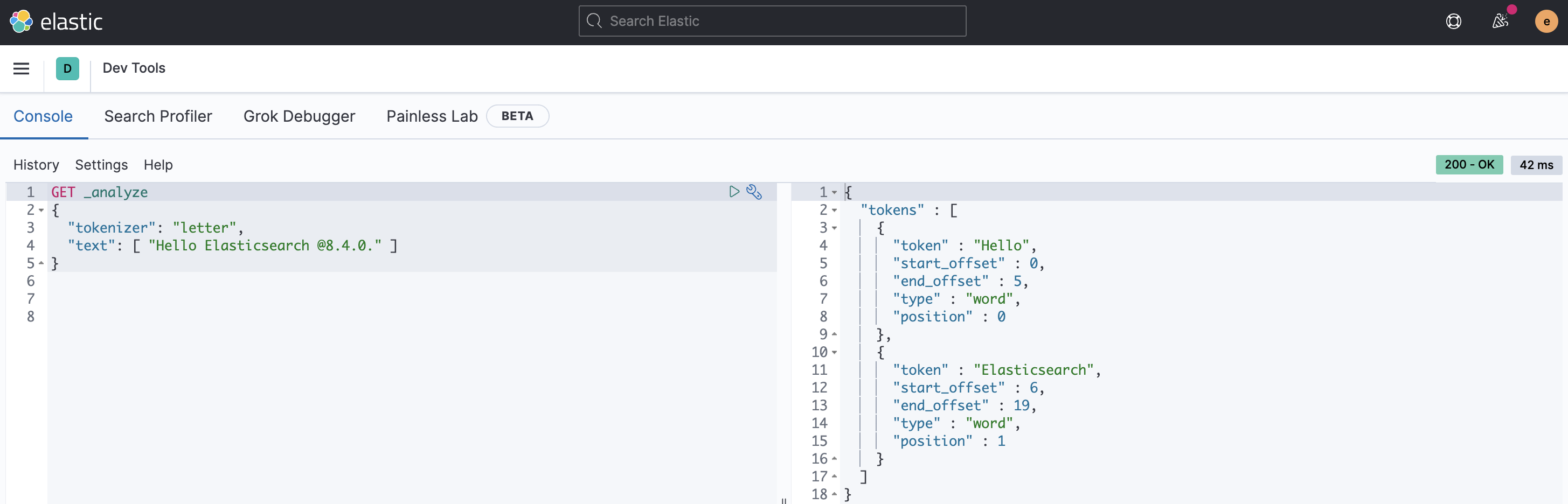
→ Whitespace : 스페이스, 탭, 줄바꿈과 같은 공백만을 기준으로 Term을 분리한다.
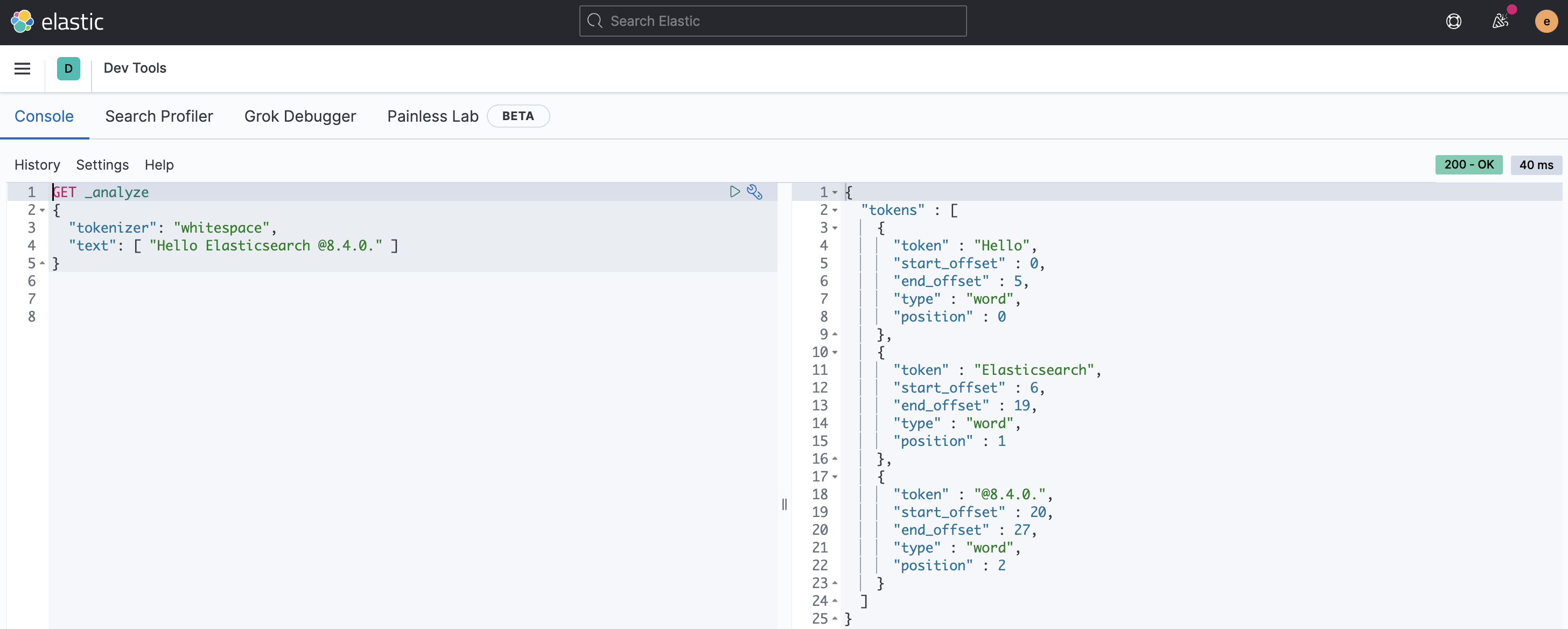
-
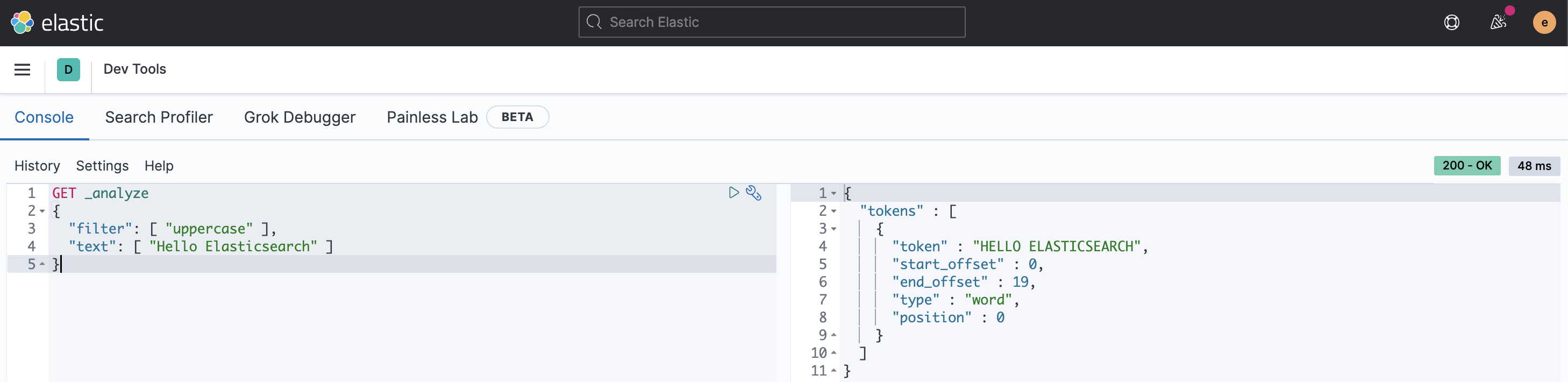
Token filters : 분리 된 Term을 지정한 규칙에 따라 처리한다.
→ 대소문자를 구분하지 않기 위해 사용하는 LowerCase, UpperCase
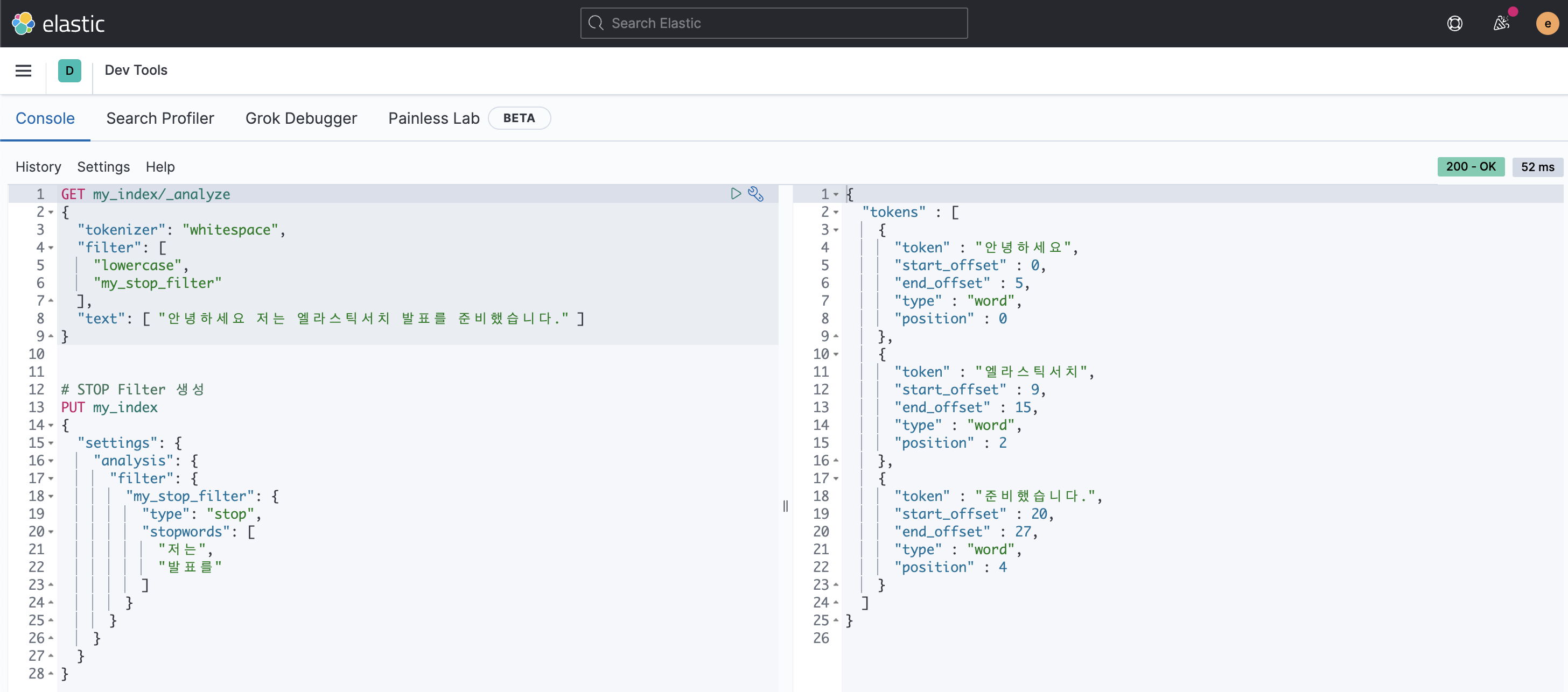
→ 의미 상 크게 중요하지 않은 불용어를 제거하는 Stop
→ 동의어를 추가하는 **Synonym**
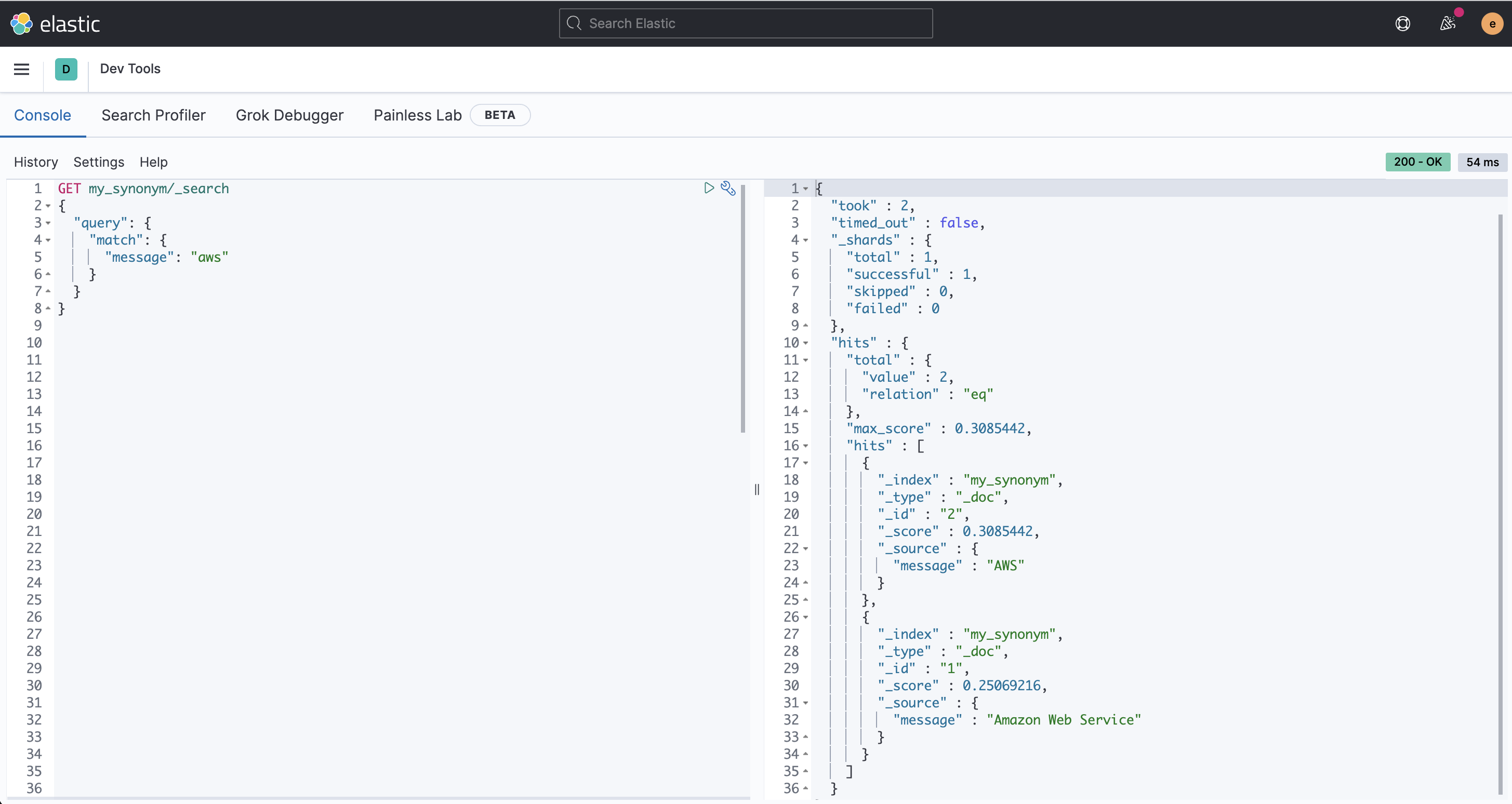
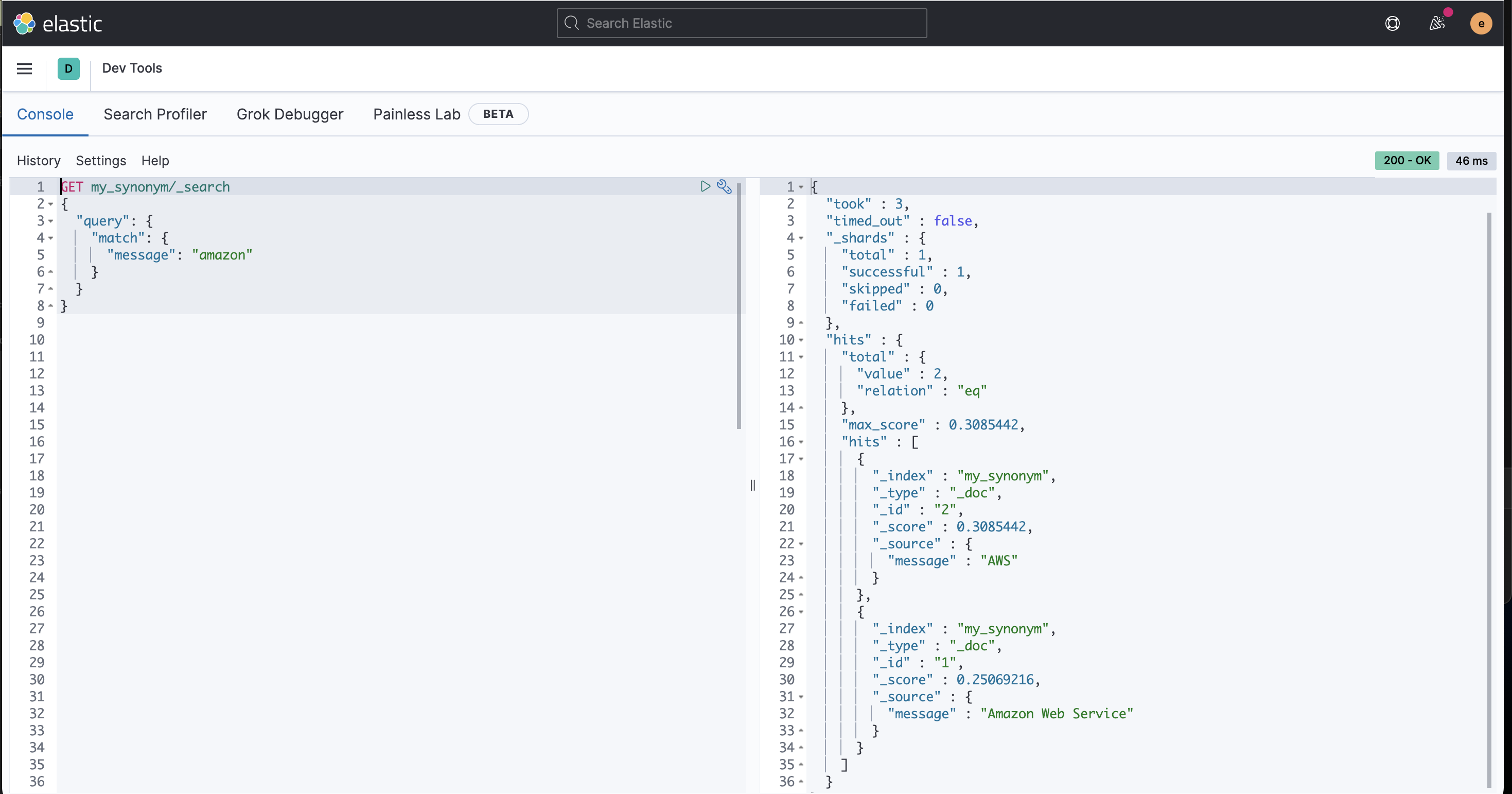
# ** synonym 추가 ** PUT my_synonym { "settings": { "analysis": { "analyzer": { "my_syn": { "tokenizer": "whitespace", "filter": [ "lowercase", "syn_aws" ] } }, "filter": { "syn_aws": { "type": "synonym", "synonyms": [ "amazon , aws" ] } } } }, "mappings": { "properties": { "message": { "type": "text", "analyzer": "my_syn" } } } } **# 데이터 추가** PUT my_synonym/_doc/1 { "message" : "Amazon Web Service" } PUT my_synonym/_doc/2 { "message" : "AWS" }
Multi Tenancy
Elasticsearch의 Index는 RDBMS에서의 Database 혹은 Schema에 해당하는데,
RDBMS라면, 다른 데이터베이스와 통신을 하려면, 각각의 커넥션을 맺어줘야하는데,
인덱스의 경우 별도의 커넥션을 맺지 않고, 한번에 조회할 수 있다.
# ** 데이터 추가 **
...
PUT my_log_2022_0827/_doc/1
{
"text" : "오늘은 토요일"
}
PUT my_log_2022_0828/_doc/1
{
"text" : "오늘은 일요일"
}
PUT my_log_2022_0829/_doc/1
{
"text" : "오늘은 월요일"
}
...
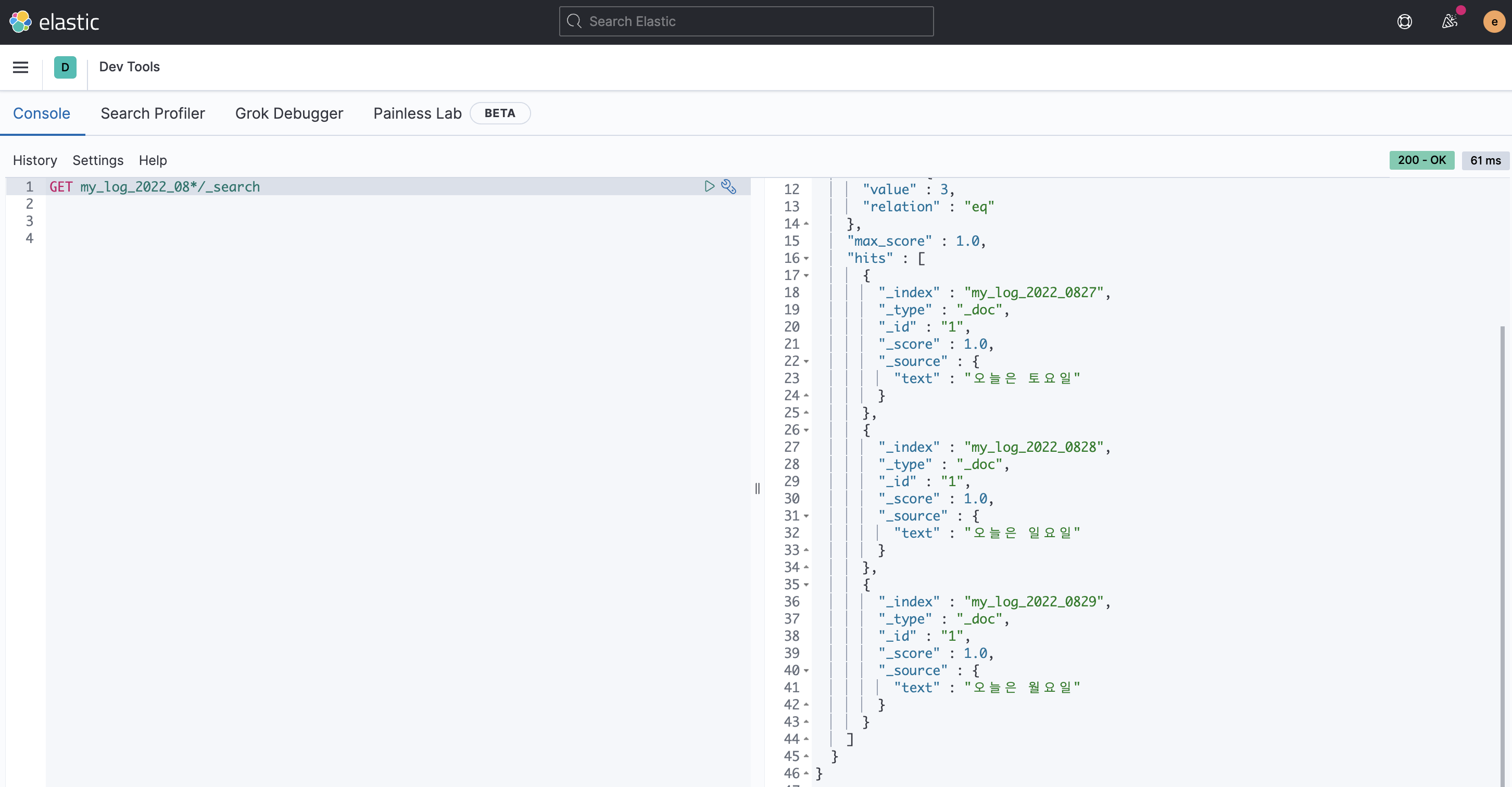
→ 2022년 8월 특정 일자만 조회하는 경우
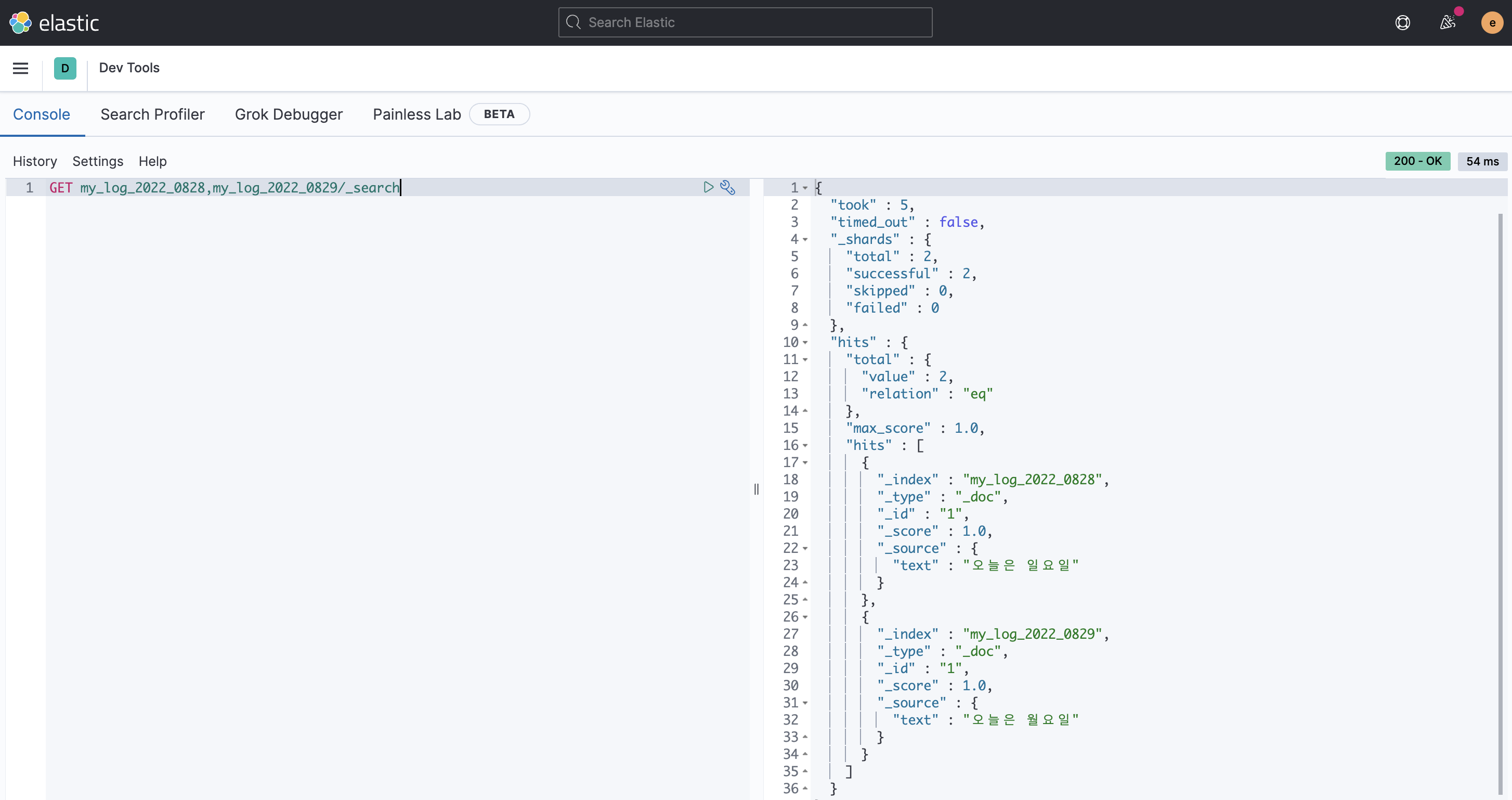
→ 2022년 8월 전체를 조회하는 경우
아마존 전 부사장 Gur Kimchi는 발음만 굴김치였는데,
Elasticsearch 창시자 Shay Banon은 트위터 계정이 진짜 김치이다.

Rest API
| Method | SQL |
|---|---|
| GET | SELECT |
| PUT | INSERT |
| POST | UPDATE |
| DELETE | DELETE |
Elasticsearch는 JSON 형태의 Rest API로 데이터를 요청 하는데,
고유한 URL을 사용하며, 각 요청을 Http Method로 구분하게 된다.
Elasticsearch 인기도
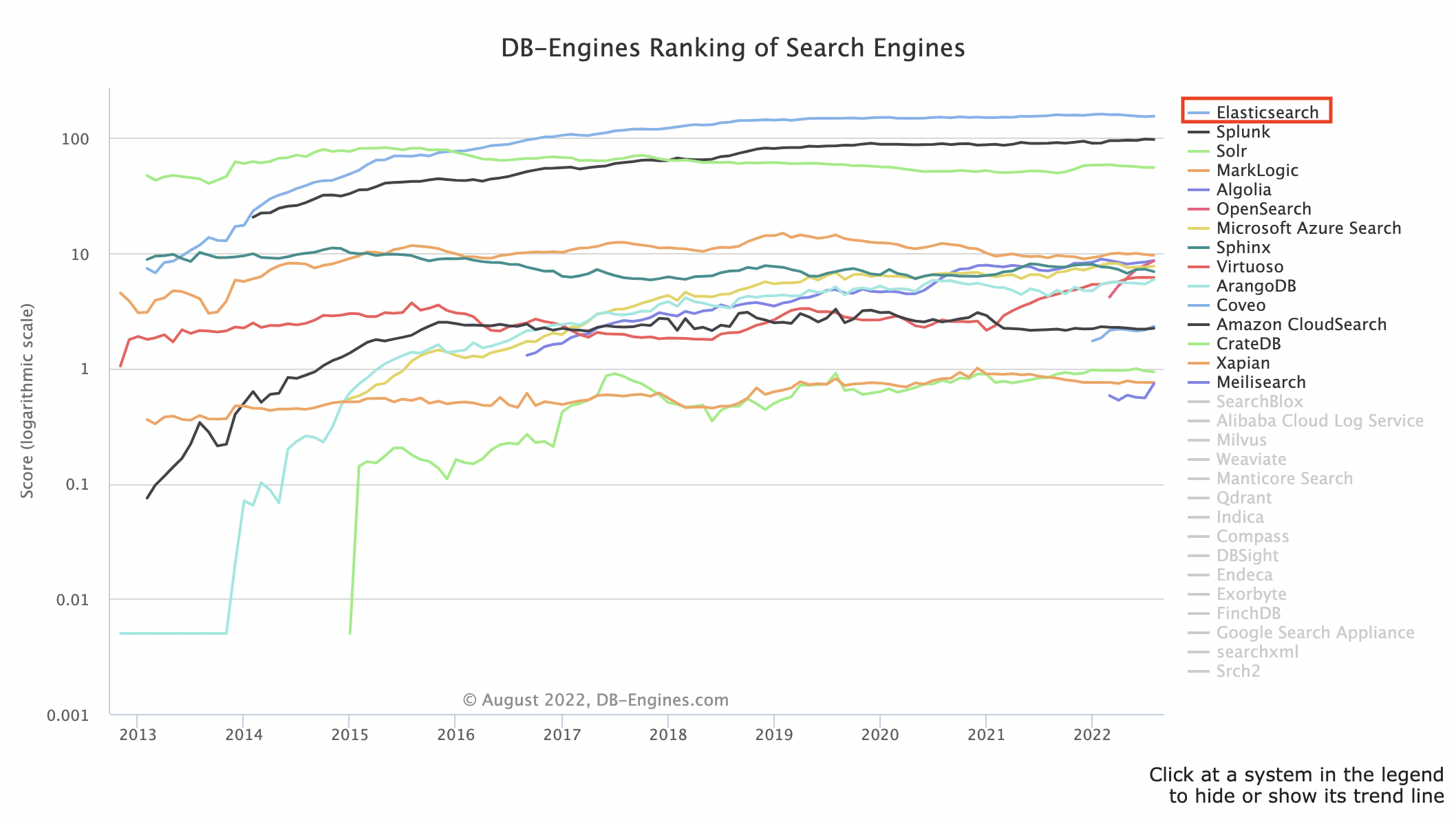
Elasticsearch는 2016년 1월을 기점으로 현재까지 검색 엔진 중 인기도 1위를 유지하고 있다.
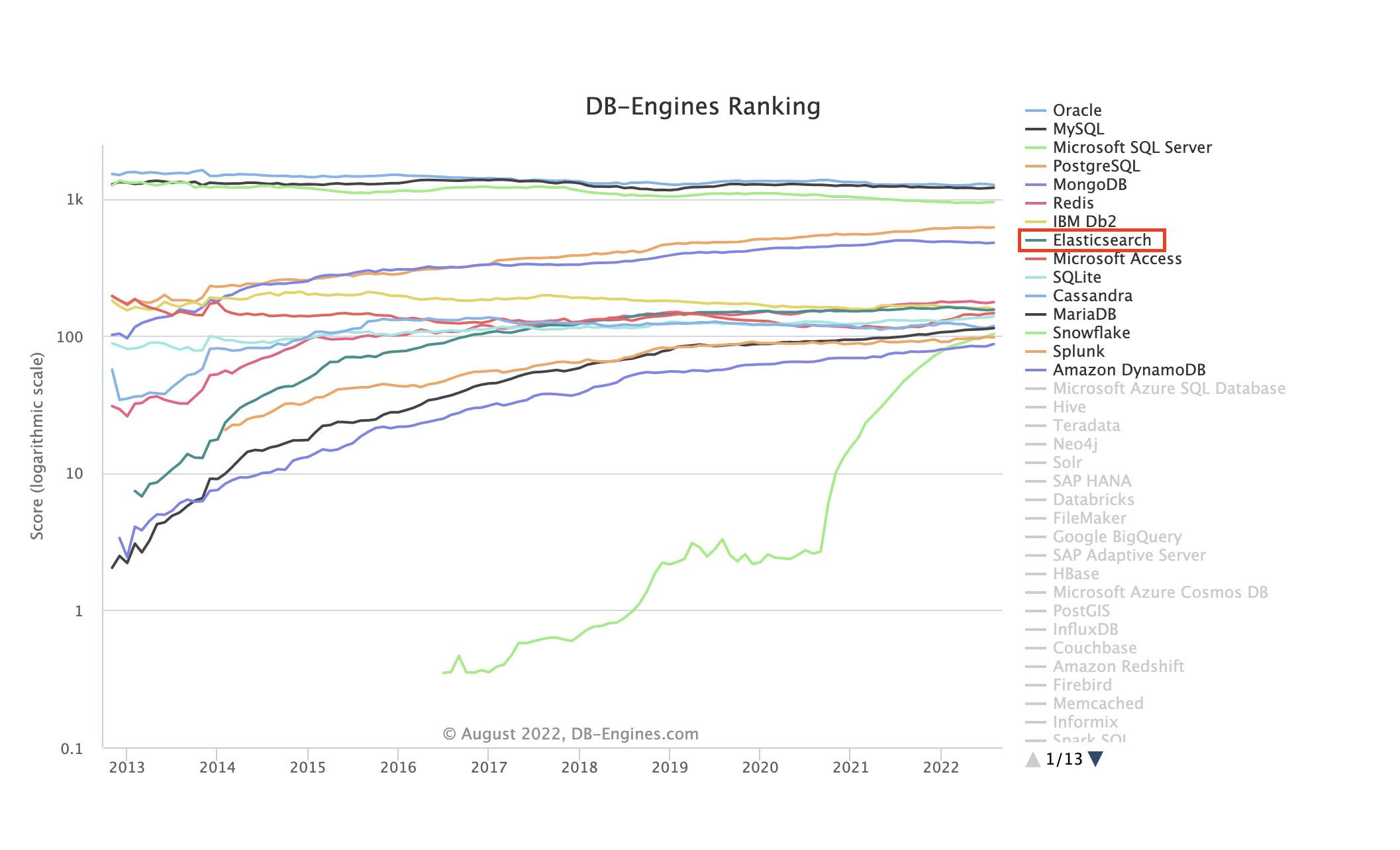
전체 Database 인기 순위에서도 8위로 높은 순위이다.
문법
elastic-search postman-documentation

- 출처
Leave a comment